目录
Alibi与旋转位置编码的比较
1. Alibi和旋转位置编码的外推性能比较
2. Alibi的处理方式
注意力线性偏置:ALiBi位置编码的实现
1. ALiBi的基本概念
2. ALiBi的实现方式
ALiBi位置编码的代码解读
1. 导入必要的库
2. 定义get_slopes函数
3. 定义get_alibi_biases函数
4. 主程序
RoPE(旋转位置编码)概述
1. RoPE的做法
2. LLaMA中的RoPE优点
RoPE位置编码的代码解读
1. precompute_freqs_cis 函数
2. reshape_for_broadcast 函数
3. apply_rotary_emb 函数
LLM中使用Alibi的频率较低及可能原因
1. LLM中Alibi使用的普遍性
2. Alibi使用频率低的可能原因
2.1 新技术的验证阶段
2.2 评测指标不匹配
2.3 对外推性的过度强调
Alibi与旋转位置编码的比较
1. Alibi和旋转位置编码的外推性能比较
Alibi位置编码的外推能力相较于旋转位置编码更为出色。虽然旋转位置编码是基于正余弦三角式位置编码的改进,融入了相对位置信息,但其继承了正余弦三角式位置编码的外推性能的缺陷。正余弦三角式位置编码虽然看似可以直接推演出无限长度的位置编码,而无需训练,但其忽视了周期性函数必须进行位置衰减的问题。当位置信息趋于远处时,其信息呈现出直线震荡的特性,几乎无法区分位置信息,因此其外推性能并不比训练式的好很多。旋转位置编码作为其改进版本,自然也存在这样的问题。
2. Alibi的处理方式
Alibi通过在k和q向量内积上添加分数偏置,来突出位置差异性。针对远距离衰减问题,Alibi利用softmax函数的特性进行差异性的软放大,通过扩大token之间的位置差异性,避免远距离时被衰减至接近0。因为这种处理方式直接作用在attention分数上,所以能够有效地放大远距离的内积值。在训练过程中,由于位置差异性减少的问题得到了大大的缓解,Alibi因此获得了更强的远距离外推能力。
注意力线性偏置:ALiBi位置编码的实现
1. ALiBi的基本概念
ALiBi(Attention with Linear Biases)位置编码是一种在自注意力模型中使用的位置编码方法。它的目标是在自注意力机制中引入位置信息,使模型能够理解单词之间的相对位置。具体来说,ALiBi通过向自注意力机制的每个输入添加一个线性偏置项来实现这一目标。这个线性偏置项是基于输入的位置计算的,因此可以反映出输入之间的相对位置信息。
2. ALiBi的实现方式
ALiBi的实现主要包括以下几个步骤:
-
首先,为每个输入位置i和每个输出位置j,计算一个线性偏置b_ij = i - j。这个偏置反映了输入和输出之间的相对位置。
-
然后,将这个偏置添加到自注意力机制的输入上。具体来说,如果自注意力机制的输入是一个矩阵X,那么新的输入就是X + b*m。
-
最后,使用这个新的输入执行自注意力计算。这样,模型就能够理解输入之间的相对位置。
这种方法的一个关键优点是它不需要任何额外的参数,因此不会增加模型的复杂性。
m的取值如下:

ALiBi位置编码的代码解读
1. 导入必要的库
import math
import torch
from torch import nn
这部分代码导入了执行此操作所需的库。math库用于数学运算,torch是PyTorch库,用于深度学习和张量运算,nn是PyTorch的神经网络库。
2. 定义get_slopes函数
def get_slopes(n_heads: int):
n = 2 ** math.floor(math.log2(n_heads))
m_0 = 2.0 ** (-8.0 / n)
m = torch.pow(m_0, torch.arange(1, 1 + n))
if n < n_heads:
m_hat_0 = 2.0 ** (-4.0 / n)
m_hat = torch.pow(m_hat_0, torch.arange(1, 1 + 2 * (n_heads - n), 2))
m = torch.cat([m, m_hat])
return m
这个函数计算了每个头部的斜率。首先,它计算了n,这是最接近n_heads的2的幂。然后,它计算了一个基础斜率m_0,并使用这个基础斜率生成了一个斜率数组m。如果n小于n_heads,则生成另一个斜率数组m_hat并将其添加到m中。结果是一个长度为n_heads的斜率数组。
3. 定义get_alibi_biases函数
def get_slopes(n_heads: int):
n = 2 ** math.floor(math.log2(n_heads))
m_0 = 2.0 ** (-8.0 / n)
m = torch.pow(m_0, torch.arange(1, 1 + n))
if n < n_heads:
m_hat_0 = 2.0 ** (-4.0 / n)
m_hat = torch.pow(m_hat_0, torch.arange(1, 1 + 2 * (n_heads - n), 2))
m = torch.cat([m, m_hat])
return m这个函数计算了ALiBi的偏置。首先,它获取了斜率数组m,然后计算了一个距离矩阵distance,这个矩阵表示每个位置与其他位置的相对距离。最后,它返回了一个偏置矩阵,这个矩阵是距离矩阵和斜率数组的元素乘积。
4. 主程序
seq_len = 10
n_heads = 8
m = get_slopes(n_heads)
print(m)
alibi_biases = torch.zeros(seq_len,seq_len)
for j in range(1,seq_len):
for i in range(j, seq_len):
alibi_biases[i, i - j] = -j
print(alibi_biases)
print(alibi_biases[:, :, None].shape, m[None, None, :].shape)
alibi_biases[:, :, None] * m[None, None, :]这部分代码首先设置了序列长度和头部数量,然后计算了斜率数组m。接着,它创建了一个全零的偏置矩阵alibi_biases,然后通过循环为这个矩阵赋值。最后,它打印了偏置矩阵和斜率数组的形状,并计算了偏置矩阵和斜率数组的元素乘积。这个乘积就是最终的ALiBi偏置矩阵。
RoPE(旋转位置编码)概述
1. RoPE的做法
RoPE,全称为Rotary Position Embedding,是一种新型的位置编码方法。在RoPE中,每个位置被编码为一个复数,这个复数的模长为1,角度与位置成正比。具体来说,如果我们把词的位置表示为p,那么我们可以得到一个复数的位置编码ei⋅p,其中i是虚数单位。
- RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点。
- 主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息。
RoPE不是像传统的位置编码那样将位置信息和词的嵌入向量直接相加。这样,RoPE可以在不增加模型大小的情况下提供丰富的位置信息。
2. LLaMA中的RoPE优点
- 提升模型性能:RoPE能够将相对位置信息依赖集成到self-attention中,从而提升transformer架构的性能。
- 适应大模型:RoPE是一种在大模型中广泛使用的位置编码方式,包括LLaMA、baichuan、ChatGLM等。
RoPE位置编码的代码解读
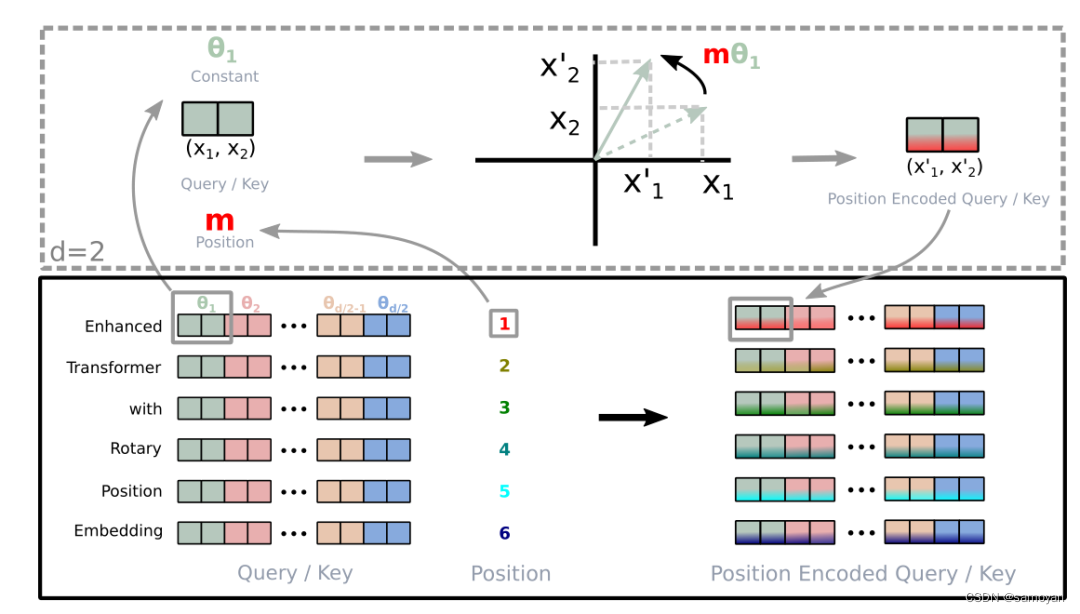
图片来源于:一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long-CSDN博客
1. precompute_freqs_cis 函数
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
这个函数的目的是预计算旋转位置编码(RoPE)的频率项和复数项。
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)):这一行代码计算了每个维度的频率,频率是按照维度的位置逐渐减小的。t = torch.arange(end, device=freqs.device):这一行代码生成了一个从0到end-1的整数序列,用于后续的外积计算。freqs = torch.outer(t, freqs).float():这一行代码计算了位置和频率的外积,得到了每个位置在每个维度上的频率。freqs_cis = torch.polar(torch.ones_like(freqs), freqs):这一行代码将频率转换为复数形式,实部为1,虚部为频率。
2. reshape_for_broadcast 函数
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
这个函数的目的是将频率的形状调整为可以广播到输入张量x的形状。
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]:这一行代码计算了新的形状,新的形状与x的形状相同,但是中间的维度都变为1。return freqs_cis.view(*shape):这一行代码将频率调整为新的形状。
3. apply_rotary_emb 函数
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
这个函数的目的是将旋转位置编码应用到输入张量xq和xk上。
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))和xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2)):这两行代码将输入张量xq和xk转换为复数形式。freqs_cis = reshape_for_broadcast(freqs_cis, xq_):这一行代码将频率的形状调整为可以广播到xq_的形状。xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)和xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3):这两行代码将位置编码应用到xq_和xk_上,然后将结果转换为实数形式。return xq_out.type_as(xq), xk_out.type_as(xk):这一行代码返回应用了位置编码的xq_out和xk_out,它们的数据类型与原始的xq和xk相同。
LLM中使用Alibi的频率较低及可能原因
1. LLM中Alibi使用的普遍性
目前市场上的语言模型(LLM)中很少使用Alibi(据目前所知,可能只有BLOOM/MPT采用了Alibi)。这可能有以下几个原因。
2. Alibi使用频率低的可能原因
2.1 新技术的验证阶段
专注于长度外推性的工作主要在2021年和2022年后逐渐出现,其效果尚未经过充分的检验。
2.2 评测指标不匹配
长度外推性的评测指标与LLM的评测指标并不完全匹配。目前,长度外推性主要依赖于困惑度(PPL)进行评估,但这可能并不全面。因为PPL这类语言模型的指标可能更关注局部上下文的预测,因此,与局部注意力相关的方案可能在这类评测中有天然的优势。
2.3 对外推性的过度强调
目前的长度外推性工作似乎更多地强调外推性,但从LLM的角度看,应该先保证在最大长度(max_length)内的效果,然后再去追求外推性。例如,从广义语言模型(GLM)的消融实验来看,Alibi的效果还不如旋转位置编码(RoPE)。



【独一无二】](https://img-blog.csdnimg.cn/direct/9011f189160945b99764099a81484f91.png)

![[Collection与数据结构] PriorityQueue与堆](https://img-blog.csdnimg.cn/direct/c3106589611b48bd89df9c5586eb5435.png)




![[RTOS 学习记录] 复杂工程项目的管理](https://img-blog.csdnimg.cn/img_convert/299e42a82bcfd1b79b68a9e95fba5a32.png#pic_center)
